Navigating Healthcare Infrastructure for AI Applications
We can’t drive a next-generation healthcare system on foundations poured in the 1900s. The real breakthroughs will come from infrastructure that finally lets AI, new care models, and patient-owned data work at scale.
24/11/2025
Luka Nićin

There’s a strange tension in healthcare right now. We’re building AI assistants, clinical copilots, and predictive models at record speed, yet almost all of them sit on top of infrastructure that was never built to support them. It’s a bit like designing autonomous trains for a rail system that still thinks steam engines are coming back.
Segmentation of Infra Stacks (by a16z):
Behind every prescription, claim, eligibility check, and appointment sits an invisible layer of backend utilities: clearinghouses that process payments, practice management systems that schedule and route care, e-prescribing networks tied into pharmacy supply chains, and interoperability layers that control how data can legally move. Nearly every workflow depends on them.
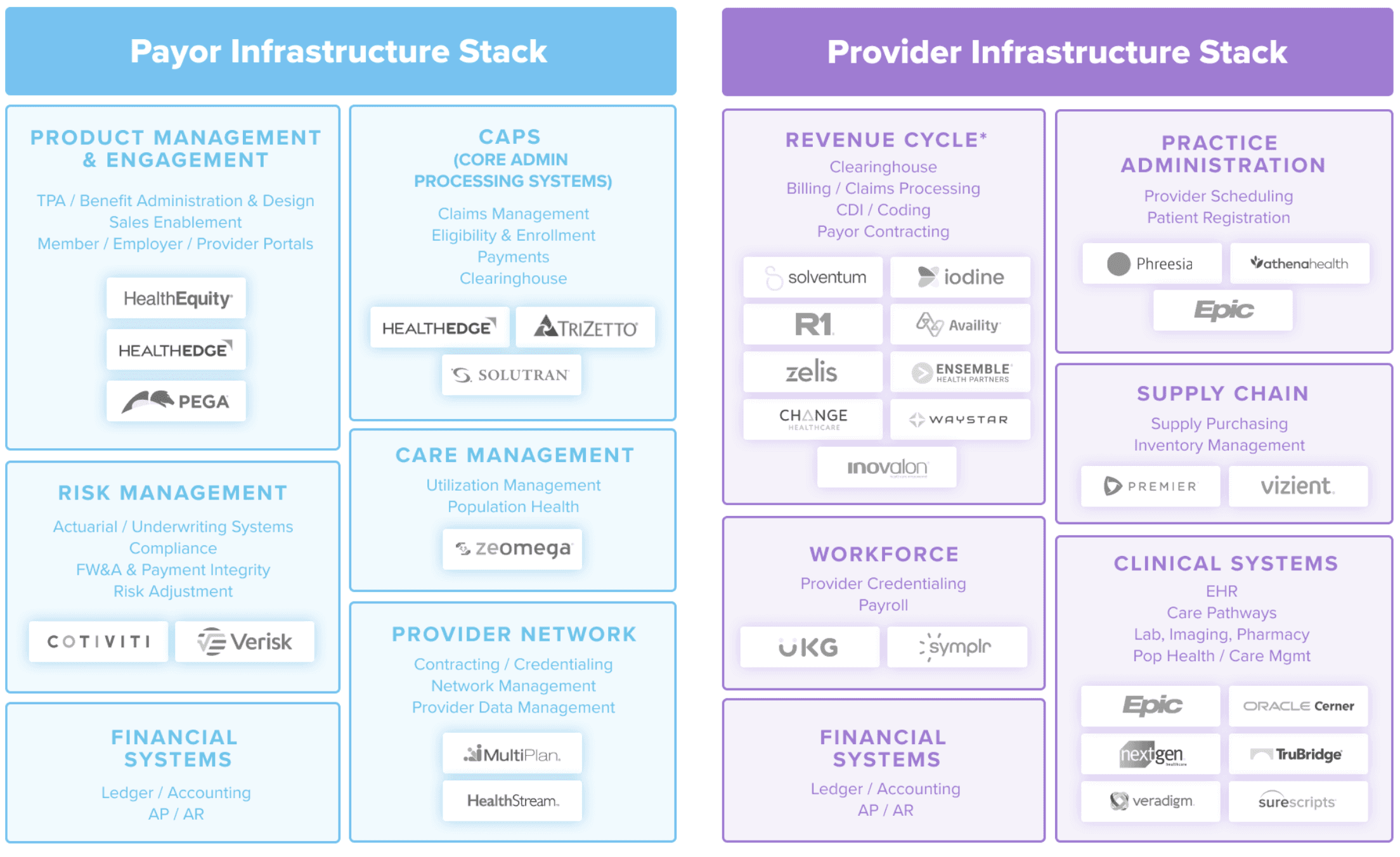
As new tools flood the application layer, the cracks underneath are becoming impossible to ignore. Hospitals are trying to run AI scribes through EHRs written before smartphones existed, plug automation into fee-for-service billing rails, and deploy virtual care models on scheduling systems that assume everyone practices in a building. The issue isn’t that the AI doesn’t work, it’s that the infrastructure can’t speak its language, increasing friction.
Some assume the solution is simple: just “move healthcare to the cloud.” But regulation makes that impossible in a single stroke. Data in healthcare isn’t just stored, it’s governed, audited, and sovereign. One European hospital’s recent move (link) to a hybrid architecture illustrates the future: pseudonymizing data locally, keeping encryption keys on-prem, and using cloud compute only as a controlled extension, not a replacement.
“In healthcare, infrastructure is constrained less by technology than by law, trust, and accountability.”
Care is changing faster than infrastructure can follow
Meanwhile, care delivery itself has changed faster than the rails beneath it. Providers are being delegated financial risk. Care is shifting into homes and virtual networks. Patients are becoming payors and data owners. Interoperability now needs biological and clinical context, not just billing codes. Our systems still assume a world of brick-and-mortar medicine and fee-for-service economics. That mismatch isn’t just inconvenient, it’s the bottleneck on almost everything we claim to be building.
Assumption (Old World) | Reality (Emerging World) |
|---|---|
Care happens in hospitals and clinics | Care happens at home, virtually, in communities |
Payors manage risk | Providers are increasingly being delegated risk |
Patients are passive beneficiaries | Patients act as payors, data owners, and decision makers |
Data is exchanged episodically | Data must be exchanged continuously and contextually |
Interoperability means billing codes | Interoperability increasingly means clinical context |
This is especially visible in the emerging excitement around “clinical-data foundries.” People imagine data factories that generate anonymized, governed, longitudinal datasets for AI and research. But foundries don’t work without standardization and infrastructure. You can’t build them out of scattered PDFs, inconsistent lab mappings, or claims data riddled with errors and missing detail. Data foundries are not AI projects, they are infrastructure projects.
The most important healthtech companies of the next decade might not build the smartest models. They will rebuild the OS those models depend on: API-first rails for claims and payments, modernized authorization and routing systems, infrastructure for providers taking risk, contracting platforms for virtual networks, consent and data-governance engines controlled by patients, and interoperability layers built for real-time clinical context.
AI as a multiplier
AI will matter most here, not as the headline, but as the multiplier. It will normalize messy data, enforce compliance in real time, map entities across incompatible systems, and act as connective tissue across fragmented workflows. Less “AI for scheduling,” more “AI as the interface for a broken operating system.”
This work isn’t glamorous. It requires patience, regulatory fluency, and empathy for the unsexy workflows that actually run healthcare. But if we want an equitable, intelligent system that works for patients and providers, this is where the leverage lives.
The real revolution in healthcare may not begin with AI. It may begin with infrastructure that finally lets AI matter.
Where lies the opportunity?
Single point-solutions already provide some value today (think scribes, prior authorization, claim appeal), but what needs to happen to unlock true end-to-end workflows?
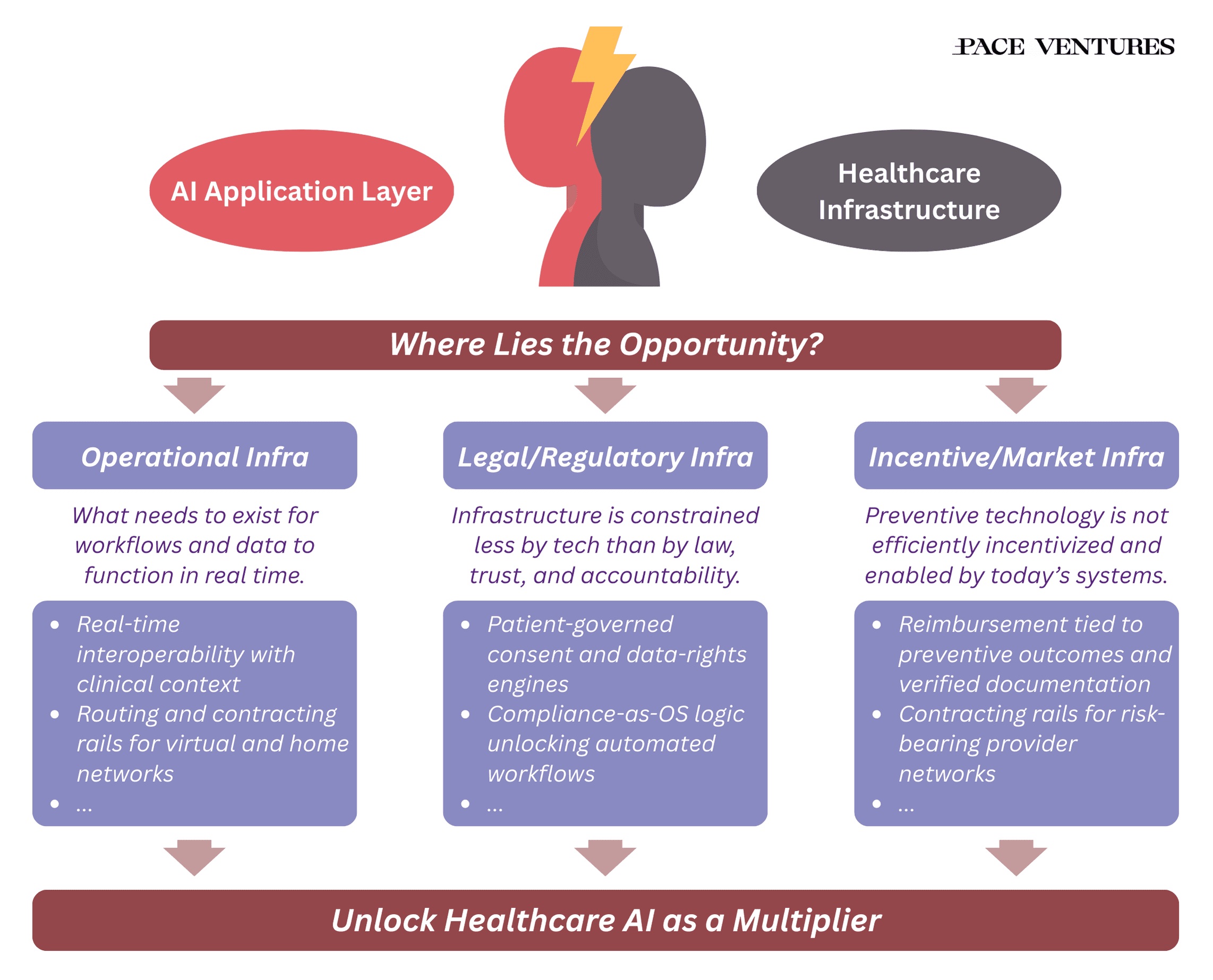
Infrastructure as the Unbuilt Logistics Layer
Healthcare doesn’t lack software, it lacks infrastructure that behaves like a logistics system. The most transformative opportunities sit in the “pipes between the pipes”: contracting rails for value-based and risk-bearing provider networks, AI-assisted claims systems that validate documentation in real time, consent and data-rights frameworks that give patients control over how their data trains models, and rails that convert continuous in-home monitoring into billable, clinically trusted events. The companies that win here won’t treat regulation as a hurdle but as product design, building compliance directly into the rails so that incentives, legal constraints, and workflows align instead of collide. These are domain-specific systems that collapse friction for every other builder that comes afterward.
Data Access Isn’t Enough: The Raw Material Is Too Messy for AI
Even with access to data, most clinical information is unstructured, billing-coded, and context-stripped, making it unusable as ground truth for AI. Healthcare needs real-time interoperability that streams normalized labs, meds, and diagnostics with biological context rather than billing metadata. The opportunity lies in infrastructure that produces clean, accountable datasets: streaming APIs that enrich data on arrival, consent-governed record-usage frameworks that trace provenance, and data foundries that transform clinical signals into trustworthy training material for clinical copilots. Here, some recently emerging players include Convoke, Cellbyte and Equator. The winners won’t be those with the flashiest models but those who earn the right for AI to scale by producing reliable, regulated, and context-aware data pipelines that models can actually learn from.
There’s a strange tension in healthcare right now. We’re building AI assistants, clinical copilots, and predictive models at record speed, yet almost all of them sit on top of infrastructure that was never built to support them. It’s a bit like designing autonomous trains for a rail system that still thinks steam engines are coming back.
Segmentation of Infra Stacks (by a16z):
Behind every prescription, claim, eligibility check, and appointment sits an invisible layer of backend utilities: clearinghouses that process payments, practice management systems that schedule and route care, e-prescribing networks tied into pharmacy supply chains, and interoperability layers that control how data can legally move. Nearly every workflow depends on them.
As new tools flood the application layer, the cracks underneath are becoming impossible to ignore. Hospitals are trying to run AI scribes through EHRs written before smartphones existed, plug automation into fee-for-service billing rails, and deploy virtual care models on scheduling systems that assume everyone practices in a building. The issue isn’t that the AI doesn’t work, it’s that the infrastructure can’t speak its language, increasing friction.
Some assume the solution is simple: just “move healthcare to the cloud.” But regulation makes that impossible in a single stroke. Data in healthcare isn’t just stored, it’s governed, audited, and sovereign. One European hospital’s recent move (link) to a hybrid architecture illustrates the future: pseudonymizing data locally, keeping encryption keys on-prem, and using cloud compute only as a controlled extension, not a replacement.
“In healthcare, infrastructure is constrained less by technology than by law, trust, and accountability.”
Care is changing faster than infrastructure can follow
Meanwhile, care delivery itself has changed faster than the rails beneath it. Providers are being delegated financial risk. Care is shifting into homes and virtual networks. Patients are becoming payors and data owners. Interoperability now needs biological and clinical context, not just billing codes. Our systems still assume a world of brick-and-mortar medicine and fee-for-service economics. That mismatch isn’t just inconvenient, it’s the bottleneck on almost everything we claim to be building.
Assumption (Old World) | Reality (Emerging World) |
|---|---|
Care happens in hospitals and clinics | Care happens at home, virtually, in communities |
Payors manage risk | Providers are increasingly being delegated risk |
Patients are passive beneficiaries | Patients act as payors, data owners, and decision makers |
Data is exchanged episodically | Data must be exchanged continuously and contextually |
Interoperability means billing codes | Interoperability increasingly means clinical context |
This is especially visible in the emerging excitement around “clinical-data foundries.” People imagine data factories that generate anonymized, governed, longitudinal datasets for AI and research. But foundries don’t work without standardization and infrastructure. You can’t build them out of scattered PDFs, inconsistent lab mappings, or claims data riddled with errors and missing detail. Data foundries are not AI projects, they are infrastructure projects.
The most important healthtech companies of the next decade might not build the smartest models. They will rebuild the OS those models depend on: API-first rails for claims and payments, modernized authorization and routing systems, infrastructure for providers taking risk, contracting platforms for virtual networks, consent and data-governance engines controlled by patients, and interoperability layers built for real-time clinical context.
AI as a multiplier
AI will matter most here, not as the headline, but as the multiplier. It will normalize messy data, enforce compliance in real time, map entities across incompatible systems, and act as connective tissue across fragmented workflows. Less “AI for scheduling,” more “AI as the interface for a broken operating system.”
This work isn’t glamorous. It requires patience, regulatory fluency, and empathy for the unsexy workflows that actually run healthcare. But if we want an equitable, intelligent system that works for patients and providers, this is where the leverage lives.
The real revolution in healthcare may not begin with AI. It may begin with infrastructure that finally lets AI matter.
Where lies the opportunity?
Single point-solutions already provide some value today (think scribes, prior authorization, claim appeal), but what needs to happen to unlock true end-to-end workflows?
Infrastructure as the Unbuilt Logistics Layer
Healthcare doesn’t lack software, it lacks infrastructure that behaves like a logistics system. The most transformative opportunities sit in the “pipes between the pipes”: contracting rails for value-based and risk-bearing provider networks, AI-assisted claims systems that validate documentation in real time, consent and data-rights frameworks that give patients control over how their data trains models, and rails that convert continuous in-home monitoring into billable, clinically trusted events. The companies that win here won’t treat regulation as a hurdle but as product design, building compliance directly into the rails so that incentives, legal constraints, and workflows align instead of collide. These are domain-specific systems that collapse friction for every other builder that comes afterward.
Data Access Isn’t Enough: The Raw Material Is Too Messy for AI
Even with access to data, most clinical information is unstructured, billing-coded, and context-stripped, making it unusable as ground truth for AI. Healthcare needs real-time interoperability that streams normalized labs, meds, and diagnostics with biological context rather than billing metadata. The opportunity lies in infrastructure that produces clean, accountable datasets: streaming APIs that enrich data on arrival, consent-governed record-usage frameworks that trace provenance, and data foundries that transform clinical signals into trustworthy training material for clinical copilots. Here, some recently emerging players include Convoke, Cellbyte and Equator. The winners won’t be those with the flashiest models but those who earn the right for AI to scale by producing reliable, regulated, and context-aware data pipelines that models can actually learn from.
There’s a strange tension in healthcare right now. We’re building AI assistants, clinical copilots, and predictive models at record speed, yet almost all of them sit on top of infrastructure that was never built to support them. It’s a bit like designing autonomous trains for a rail system that still thinks steam engines are coming back.
Segmentation of Infra Stacks (by a16z):
Behind every prescription, claim, eligibility check, and appointment sits an invisible layer of backend utilities: clearinghouses that process payments, practice management systems that schedule and route care, e-prescribing networks tied into pharmacy supply chains, and interoperability layers that control how data can legally move. Nearly every workflow depends on them.
As new tools flood the application layer, the cracks underneath are becoming impossible to ignore. Hospitals are trying to run AI scribes through EHRs written before smartphones existed, plug automation into fee-for-service billing rails, and deploy virtual care models on scheduling systems that assume everyone practices in a building. The issue isn’t that the AI doesn’t work, it’s that the infrastructure can’t speak its language, increasing friction.
Some assume the solution is simple: just “move healthcare to the cloud.” But regulation makes that impossible in a single stroke. Data in healthcare isn’t just stored, it’s governed, audited, and sovereign. One European hospital’s recent move (link) to a hybrid architecture illustrates the future: pseudonymizing data locally, keeping encryption keys on-prem, and using cloud compute only as a controlled extension, not a replacement.
“In healthcare, infrastructure is constrained less by technology than by law, trust, and accountability.”
Care is changing faster than infrastructure can follow
Meanwhile, care delivery itself has changed faster than the rails beneath it. Providers are being delegated financial risk. Care is shifting into homes and virtual networks. Patients are becoming payors and data owners. Interoperability now needs biological and clinical context, not just billing codes. Our systems still assume a world of brick-and-mortar medicine and fee-for-service economics. That mismatch isn’t just inconvenient, it’s the bottleneck on almost everything we claim to be building.
Assumption (Old World) | Reality (Emerging World) |
|---|---|
Care happens in hospitals and clinics | Care happens at home, virtually, in communities |
Payors manage risk | Providers are increasingly being delegated risk |
Patients are passive beneficiaries | Patients act as payors, data owners, and decision makers |
Data is exchanged episodically | Data must be exchanged continuously and contextually |
Interoperability means billing codes | Interoperability increasingly means clinical context |
This is especially visible in the emerging excitement around “clinical-data foundries.” People imagine data factories that generate anonymized, governed, longitudinal datasets for AI and research. But foundries don’t work without standardization and infrastructure. You can’t build them out of scattered PDFs, inconsistent lab mappings, or claims data riddled with errors and missing detail. Data foundries are not AI projects, they are infrastructure projects.
The most important healthtech companies of the next decade might not build the smartest models. They will rebuild the OS those models depend on: API-first rails for claims and payments, modernized authorization and routing systems, infrastructure for providers taking risk, contracting platforms for virtual networks, consent and data-governance engines controlled by patients, and interoperability layers built for real-time clinical context.
AI as a multiplier
AI will matter most here, not as the headline, but as the multiplier. It will normalize messy data, enforce compliance in real time, map entities across incompatible systems, and act as connective tissue across fragmented workflows. Less “AI for scheduling,” more “AI as the interface for a broken operating system.”
This work isn’t glamorous. It requires patience, regulatory fluency, and empathy for the unsexy workflows that actually run healthcare. But if we want an equitable, intelligent system that works for patients and providers, this is where the leverage lives.
The real revolution in healthcare may not begin with AI. It may begin with infrastructure that finally lets AI matter.
Where lies the opportunity?
Single point-solutions already provide some value today (think scribes, prior authorization, claim appeal), but what needs to happen to unlock true end-to-end workflows?
Infrastructure as the Unbuilt Logistics Layer
Healthcare doesn’t lack software, it lacks infrastructure that behaves like a logistics system. The most transformative opportunities sit in the “pipes between the pipes”: contracting rails for value-based and risk-bearing provider networks, AI-assisted claims systems that validate documentation in real time, consent and data-rights frameworks that give patients control over how their data trains models, and rails that convert continuous in-home monitoring into billable, clinically trusted events. The companies that win here won’t treat regulation as a hurdle but as product design, building compliance directly into the rails so that incentives, legal constraints, and workflows align instead of collide. These are domain-specific systems that collapse friction for every other builder that comes afterward.
Data Access Isn’t Enough: The Raw Material Is Too Messy for AI
Even with access to data, most clinical information is unstructured, billing-coded, and context-stripped, making it unusable as ground truth for AI. Healthcare needs real-time interoperability that streams normalized labs, meds, and diagnostics with biological context rather than billing metadata. The opportunity lies in infrastructure that produces clean, accountable datasets: streaming APIs that enrich data on arrival, consent-governed record-usage frameworks that trace provenance, and data foundries that transform clinical signals into trustworthy training material for clinical copilots. Here, some recently emerging players include Convoke, Cellbyte and Equator. The winners won’t be those with the flashiest models but those who earn the right for AI to scale by producing reliable, regulated, and context-aware data pipelines that models can actually learn from.