AI & Multi-Omics Data in Drug Development
The application of multi-omics data with AI offers a very exciting opportunity for VC investments.
Gabriel Méhaignerie

Summary
TL;DR
The application of multi-omics data with AI offers a very exciting opportunity for VC investments.
AI and multi-omics data are revolutionizing disease understanding: AI and multi-omics data (detailed data about our genes, proteins, and other biological elements) are working together to speed up the creation of new medicines and treatments. These new tools are transforming drug discovery, and development by enabling efficient biomarker identification, drug target discovery, and cost-effective vertical integration.
Startups in that field face tough challenges: AI and multi-omics companies are faced with data management, regulatory challenges, and the high standards to validate their insights with Pharma companies.
Agnostic tool providers or disease specific biopharma are the two main winning approaches: Two types of companies stand out in this field: AI-focused Tool Providers, who create systems for drug discovery, and AI-focused Biopharma, who use these systems to find new drugs.
Dynamic databases and deep sector knowledge are drivers of success: The big databases used by AI systems and the ability to test ideas in labs are crucial for success in drug discovery using AI and genomics.
Introduction
We stand at the cusp of a transformative era in the treatment and drug discovery industry. Two key drivers have come together in a potent, symbiotic relationship: the exponential growth of data related to the functioning of the human body, and our ability to extract valuable insights from this complex data stream, thanks to the advances of Artificial Intelligence (AI).
Multi-genomic data is a game-changer in our quest to understand the intricate molecular complexities and variations associated with diverse health conditions. It provides invaluable insights into the complex interplay among various biomolecules and their functions within the human body.
Take, for instance, identical twins. While they share the same genome and are more likely to share health conditions, they don’t always exhibit the same diseases, particularly complex disorders like schizophrenia. This fact underscores the multifaceted nature of human health and disease. We cannot approach diseases only through the prism of genetics but rather through multiple factors — our genome, epigenetics (stable changes in gene expression that do not involve DNA sequence modifications), metabolomics, and microbiome, among others. This is what multi-omics data encompasses.
However, it’s crucial to note that multi-omics data alone doesn’t deliver the necessary actionable insights. This is where the critical role of Artificial Intelligence (AI) comes into sharp focus. AI is primed to help us discern relevant patterns within complex data, translating this complexity into more manageable forms and eventually revealing patterns that can guide understanding and actions.
This powerful convergence of AI and multi-omics data is steering us towards precision medicine, markedly enriching our understanding of disease processes and accelerating the discovery and development of innovative therapeutic solutions.
We at Pace Ventures have been exploring the space and its challenges and found exciting approaches and companies trying to provide new treatments to diseases affecting millions of us. Read more about our findings below.

Source: Merck
A Deeper Dive: What Is Multi-Omics Data and Why Is It Critical?
Consider our body a bustling city, with each cell as a distinct building hosting various activities. Each “building” or cell has numerous departments, like a design department (our genes), a manufacturing department (proteins), a communication department (RNA), and others. In biological terms, these departments are the various “omics” — genomics, proteomics, transcriptomics, etc.
To understand how this city operates — how it responds to changes, grows, or even breaks down (as in diseases), it’s not sufficient to look at one department at a time. A comprehensive understanding requires insight into how these departments interact and influence each other. This comprehensive insight is the essence of multi-omics.
Multi-omics offers a holistic overview, akin to a city planner considering all departments across all buildings. Scientists leveraging multi-omics gain rich insights into our body’s functioning in health and disease. They can unearth precise disease details, guiding the design of more specific treatments for individuals — akin to tailoring a suit to fit perfectly. This is the concept of precision medicine — delivering the right treatment, to the right person, at the right time.
However, multi-omics, like city planning, is a complex field. It involves a lot of information, necessitating specialized tools and techniques for effective processing.
Now enters AI.
AI plays a pivotal role in analyzing this wealth of data. Firstly, AI can integrate different types of multi-omics data, such as genomic, proteomic, metabolomic, and other omic data types. This integration provides a more comprehensive understanding of a patient’s physiological state, facilitating accurate disease diagnosis and prognosis and enabling precise and personalized treatment strategies.
Furthermore, AI algorithms can drastically reduce the dimensionality of multi-omics, enabling researchers to extract valuable insights from intricate biological processes. These insights can help understand disease processes better, identify potential therapeutic targets, and develop personalized treatment plans.
AI can also incorporate other data types into multi-omics analyses, like imaging, clinical, environmental, and social determinant data. This creates a more holistic view of patient health, facilitates better treatment decisions, and improves patient outcomes.
The relevance of using AI and multi-omics is already clear. For example, the Rady Children’s Institute for Genomic Medicine used AI to cut diagnosis time for rare genetic disorders in newborns to 19.5 hours. The technology rapidly analyzed multi-omics data and identified genetic variants. It enabled the swift diagnosis and treatment of an 8-day-old baby with a rare condition, demonstrating the transformative potential of AI in genomic medicine, particularly for rare diseases in pediatric settings.
The marriage of AI and multi-omics data is a revolution in healthcare that is already in effect, accelerating the path toward personalized medicine and fundamentally reshaping the drug discovery industry.
Market Trends
Innovation Leaps and Growing R&D Inefficiencies in Pharma: A Paradox
In recent years, groundbreaking innovation has radically transformed scientific research, bringing together the realms of multi-omics data and Artificial Intelligence. With the plummeting cost of genome sequencing and the rapid rise in GPU computing performance, the floodgates to an era of unprecedented data collection and fast data processing have been opened wide (see figures 1 and 2).
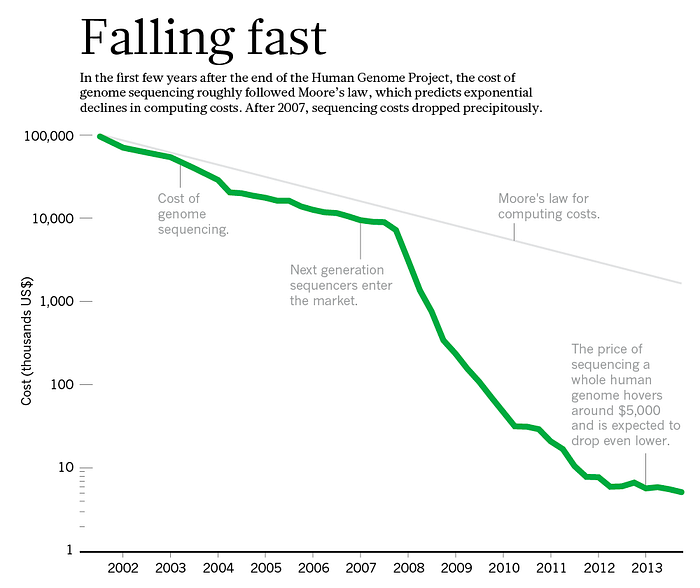
Figure 1: Cost of genome sequencing
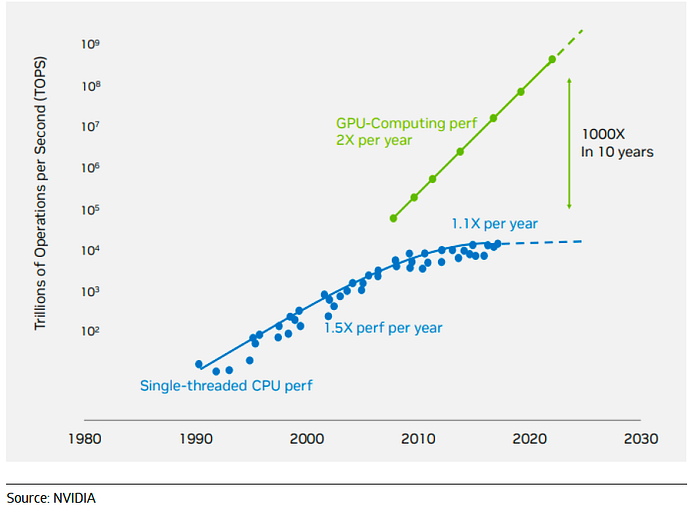
Figure 2: GPU performance in operations per second (source)
Thanks to these key developments, we are now awash in information. For perspective, approximately 30 million individuals have had their genomes sequenced, with each genome containing around 3 billion nucleotide pairs.
Key players in the biomedical sector — from biopharma firms and academic researchers to government research groups such as the National Cancer Institutes, NIH, and the U.K. Biobank — are generating large omics datasets using cutting-edge tools. These tools include genomic sequencers for DNA, single-cell RNA sequencing, and spatial proteomics platforms, but also contextualize such data through phenotype level information, like remote monitoring devices (smartwatches and smartphones), and digitally enabled tools such as insulin pumps and prescription digital therapeutics.
Despite these significant advances and the abundance of data generated, there is an unexpected stagnation in R&D efficiency within the pharmaceutical and genomics sectors. The cost of drug discovery and the time required to develop drugs have paradoxically increased — a phenomenon first noted in the 1980s and referred to as “Eroome’s Law” by Jack Scannell in a 2012 Nature publication (Moore’s Law spelled backward). Between 2001 and 2020, R&D costs increased by 13.7% annually, while the number of drugs approved increased by only 7.2% YoY over the same period. It is estimated that developing a new drug takes around 10 years and costs more than US$ 2 billion.
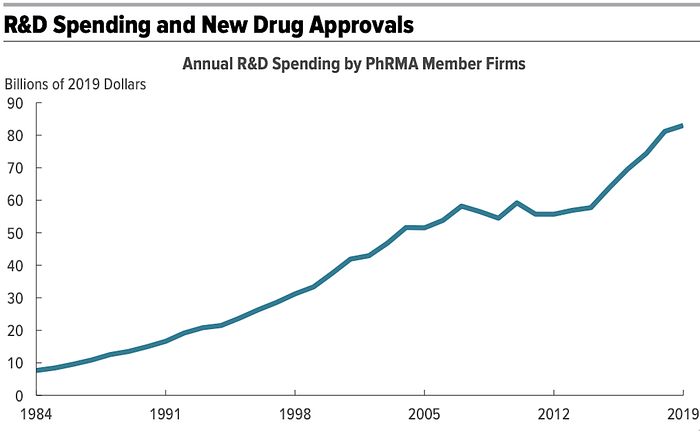
Source: Congressional Budget Office
Given these challenges, there’s a pressing need for innovation in pharmaceutical R&D. A promising solution could lie in harnessing the transformative power of AI and multi-omics, potentially ushering in a new era of efficiency and productivity in therapeutic discovery and development.
Market Dynamics: Large Pharma-AI Deals Fueling Strong Growth
The AI in drug discovery market is experiencing remarkable growth, with new players landing billion-dollar contracts. Over the last two years, a staggering $32 billion in deal value has been created through strategic partnerships between large pharmaceutical companies and AI-focused firms. For instance, in January 2022, Exscientia, an AI-driven drug discovery company, clinched a huge US$5.2 billion deal, the largest in the history of AI deals, with Sanofi.
Hence, this attracts massive capital investments, with funds injected into AI-powered drug discovery firms that have tripled over the past four years. This surge resulted in US$24.6 billion in investments in 2022 alone.
Simultaneously, the global single-cell multi-omics market (omics data at the cell level) is projected to skyrocket from $1.43 billion in 2022 to $7.72 billion by 2033, growing at a CAGR of 17.27% during the forecast period 2023–2033.
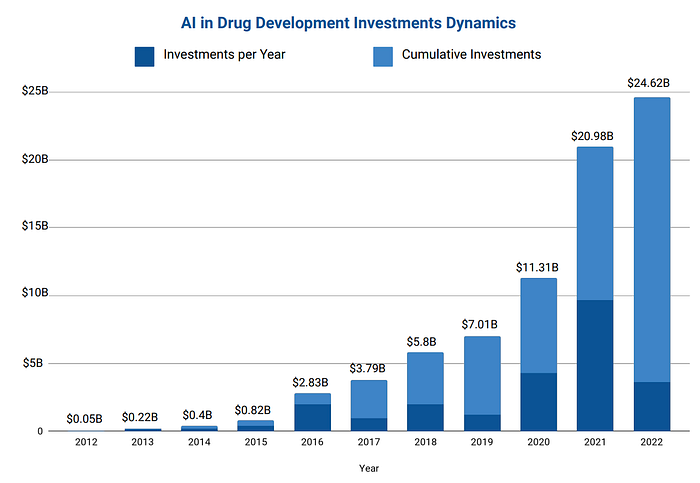
Cumulative Capital Investments in AI in Drug Development Companies (Source)
Looking toward the future, the potential revenue derived from incorporating AI in drug discovery appears boundless. This market is estimated to represent a $50 billion opportunity for big pharmaceutical companies. Using AI in early-stage drug development could yield 50 novel therapies, translating into over $50 billion in sales.
Given this vast growth potential, the future of AI-driven drug discovery is promising.
Opportunities
Unlocking Understanding of Complex Diseases: Biomarker Discovery
Biomarkers, crucial biological molecules, can reveal a disease’s presence, progression, or severity. They also serve as a gauge for the effectiveness of treatments. For instance, a certain condition might prompt elevated levels of a specific protein in the blood. This protein’s level might then decrease in response to effective treatment. Biomarkers enable researchers to categorize disease severity, measure clinical benefits or harm from therapeutic intervention, and monitor treatment responses.
Traditionally, researchers struggled to identify new biomarkers for diseases, as interpreting colossal amounts of data was impossible, and sifting through ‘noise’ to gain precious insights was very challenging.
AI techniques prove invaluable for analyzing and extracting biomarkers from integrated data. When combining different omics layers, researchers can use biomarkers to provide a more granular understanding of a disease, moving away from binary outcomes. This helps to categorize diseases into subtypes, craft predictive models for diagnosis and treatment response, and identify disease-associated pathways.
For example, Aladdin (acquired by International Biotechnology Corp.) has constructed a platform for early diagnostics of Alzheimer’s disease and COVID-19 by identifying new biomarkers for the onset detection of the conditions. This Disease Diagnosis platform utilizes AI and multi-omics data, imaging, blood samples, and medical records.
Revolutionizing the Drug Discovery Process: Drug Target Discovery
Drug targets, often proteins or genes, are specific molecules within the body that are designed to interact with drugs. These interactions can modify the target’s behavior, leading to therapeutic effects. Drug targets often form part of larger networks of interactions (or pathways) that lead to a disease phenotype, making the effect of the drug-target interaction on disease symptoms complex. Drug targets are typically discovered and validated through intensive biological and genetic research.
With techniques like network analysis, or graph-based Machine learning, it is possible to represent complex molecular reactions like a network. Analyzing these molecular interaction networks allows us to identify key nodes or proteins that are essential in disease pathways. By integrating multi-omics data with existing knowledge of molecular interactions, AI can identify potential drug targets that are crucial for disease progression and have the potential to be modulated by therapeutic interventions.
In September 2019, Deep Genomics’ (US-based) AI-driven platform leveraged a graph-based interpretation of multi-omics data to predict a novel drug target and a drug candidate for Wilson disease in less than 18 months. The platform analyzed multi-omics data and screened 100,000 genomics mutations to identify the precise disease-causing mechanism of a specific mutation.
Vertical Integration in Drug Development
Vertical integration in the drug development value chain presents a significant opportunity for companies to maximize profits. Most costs associated with drug development arise during the clinical phases, where extensive drug testing takes place. The quality assurance of the drug becomes a major bottleneck in the process. By enhancing the efficiency of the drug, companies can unlock substantial cost reductions.

Source: The Cowen Insight
AI and omics data are reshaping the way we discover drugs. They help us create predictive models that understand how drugs work at a molecular level, leading to more targeted treatments.
AI can also search through large databases to find potential new drugs. This process, called virtual screening, uses methods like molecular docking and machine learning. It’s especially useful in repurposing existing drugs for new uses.
More and more drug companies are making these techniques a core part of their work, focusing specifically on diseases. Using AI and omics data not only improves the quality of the drugs they make but also offers big benefits. It can help lower costs, create more value, and open up chances for important partnerships. This is great for both big companies and newcomers.
In fact, this approach of combining technology and a disease-specific focus is now the way forward for the most successful companies in AI drug discovery.
Insilico Medicine, an end-to-end AI-driven drug discovery company, announced the commencement of clinical trials for the first fully AI-generated drug to treat idiopathic pulmonary fibrosis, a chronic lung disease. They have pioneered the path in the pharmaceutical industry by being the foremost to reach this advanced stage in the development process with a drug entirely conceived by artificial intelligence. Simultaneously, their proprietary end-to-end platform was actively deployed and refined in parallel with the progression of the drug through its development stages. In June 2022, they reached a US$ 900 million valuation and filed in June 2023 for an IPO.
The Challenges
Data-Related Obstacles Faced by AI & Omics Companies
AI and Omics companies grapple with challenges related to data management and utilization. While AI tools are adept at processing and interpreting vast datasets, their outputs are only as accurate as the data inputs, i.e., the “garbage in equals garbage out” principle. This means that misinterpretation or misuse of data can lead to flawed results, particularly consequential in drug discovery.
First, data generation, which involves creating and tracking data back to its origin, is crucial. It calls for sector-specific expertise and a thorough understanding of how the data was produced.
Next is data aggregation, which involves collating and normalizing data to construct a comprehensive multi-omics database. However, accessing genomic data is costly and involves regulatory complexities, often necessitating a dedicated commercial or sales team to access and integrate these datasets into a given database.
Further complexity arises from data contextualization, integrating other data sources, like Electronic Health Records (EHR). However, EHR data is notoriously complex and messy, lacking standardization, which impedes systematic usage across different populations and systems.
Lastly, AI and Omics companies must grapple with stringent regulatory scrutiny, especially when accessing medical data between countries like the European Union and the United States. These restrictions limit companies’ data storage abilities and influence their choice of server hosting companies, which could be limiting factors in a company’s development.
Correlation Does Not Imply Causality
Results from in silico, or computer-simulated studies, often hinge on retrospective analysis, analyzing past data, which can inadvertently introduce bias compared to prospective studies (in vivo experiments). These future studies analyze new data based on predefined parameters, reducing bias risk.
However, the reliability of in silico results can be significantly bolstered if cross-verified across multiple independent data sets or backed up by useful data in an iterative or supplementary manner. Essentially, if the simulated results can be repeated or validated with different data sets, or supplemented by experimental data, their reliability likely increases.
Interesting Approaches and Companies in the Field
Two Different Approaches in the AI & Genomics for the Drug Discovery Space
In AI and Genomics for drug discovery, two types of approaches are distinctly noticeable for startups: AI-focused Tool Providers and AI-focused Biopharma. Nevertheless, these two company approaches share common drivers for success, as they both require deep expertise combined with rich and dynamic databases.
AI-focused Tool Providers
AI-focused Tool Providers possess extensive multi-omics databases, often complemented by other data sources. They are marked by high-caliber computer science expertise and a focus on developing innovative AI platforms applicable across various biopharma products.
An example is the Swiss-based, early-stage company, Genomsys. The company has developed an ISO standard for complex genomics data and use it to build AI tools. Another approach is Pheiron, a Berlin-based company at the pre-seed stage. Pheiron offers a plug-and-play platform that integrates large amounts of multi-omics data from various databases and leveraging AI models to extract biomarkers for complex diseases.
Similarly, Genpax (UK-based, late-stage) developed faster sequencing for high-resolution pathogen analysis to deliver reproducible results through their platform, serving diverse industries.
These tool providers place great emphasis on Collaboration and Refinement, constantly improved their service based on the results achieved through their partnerships. Biotx.ai, for instance, is pioneering a Wide Data approach, shifting from the Big Data approach many algorithms rely on, to learn complex patterns from a small number of genomic data.
Simultaneously, these providers also aim at Expansion Across different Therapeutic Areas, broadening the scope of their AI capabilities across applied on different diseases and drug development phases.
Protai, an Israel-based Series A company, uses mass spec-derived proteomics data and other protein datasets to simulate disease on the molecular level. Their vertically integrated platform is tailored for drug discovery but remains applicable to various therapeutics.
France-based Series A WhiteLab Genomics, focuses on gene therapy research. They offer a platform that enables in-silico predictions for target discovery and the design of DNA & RNA therapies.
Deepflare, early stage and Poland-based, applies computational algorithms and machine learning for personalized cancer therapies and drug design optimization while integrating lab automation for accelerated, data-driven drug development.
Scailyte, a Swiss-based early-stage company, generates insights from multi-omics single-cell data using AI for CAR-T cell therapies. Their AI platform, ScaiVision, is used by clinical and industry partners to drive a pipeline of five targets today, addressing various clinical needs. Similarly, UK-based early-stage company Coding.bio also integrates AI for rapid discovery, testing, and optimization of novel CARs, enhancing clinical outcomes.
AI-focused Biopharma
AI-focused Biopharma, in contrast, build their own resources, such as supercomputing power and algorithms. They rely on multi-omics databases they developed internally through exclusive partnerships with hospitals and other third parties. They aim to discover drug candidates within their therapeutic area of focus using their proprietary AI tools. AI-focused Biopharma aim to identify unique, differentiated drug candidates for clinical testing and eventual market release. That is what our great portfolio company Celeris Therapeutics does. They use machine learning to design proximity-inducing compounds (PICs™) and new chemical entities, focusing on treating high-need diseases, particularly in oncology and CNS disorders, through targeted protein degradation.
Yet, these AI-focused biopharma often rely on External Partnerships for AI tools or applications outside of their core focus. They seek external expertise for areas beyond drug discovery, like clinical trial design, biomarker selection, and other preclinical or clinical applications.
Several companies focus on specific diseases, like oncology, cardiovascular diseases, and neurodegenerative diseases. In oncology, France-based early-stage company Orakl.bio utilizes tumor avatars that combine advanced biology and deep patient data to identify relevant drug targets using proprietary tumor data. They offer a platform that matches their tumor models with detailed clinical and omics data with AI for a comprehensive understanding of the biological results and validate the results with a proprietary wet lab.
In the fight against cardiovascular diseases, G3 therapeutics and Cardiatec Biosciences are at the forefront. US-based G3 therapeutics combines deep biological big data, machine learning, and artificial intelligence for drug discovery through the preclinical stages in cardiovascular therapeutics. UK-based CardiaTec applies artificial intelligence on large-scale multi-omic data to develop the next generation of cardiovascular disease drug targets, creating a proprietary database of heart tissues for a multi-omics dataset.
Against metabolic disorders, Multiomic Health, a UK-based seed stage company identifies unique patient profiles to generate proprietary multi-omics data for repositioning existing drugs, and discovering new ones via their MOHSAIC® platform.
In the battle against neurodegenerative diseases, OccamzRazor and Human Centric Drug Discovery are prominent examples. US-based OccamzRazor leverages various ML algorithms (NLP, Graph-based models) with multi-omics data to identify drug targets for the treatment of Parkinson’s disease. Human Centric Drug Discovery, a UK-based early-stage company, integrates data from induced pluripotent stem cells, genetic studies, and population health data to identify and validate efficient drug targets for neurological diseases.
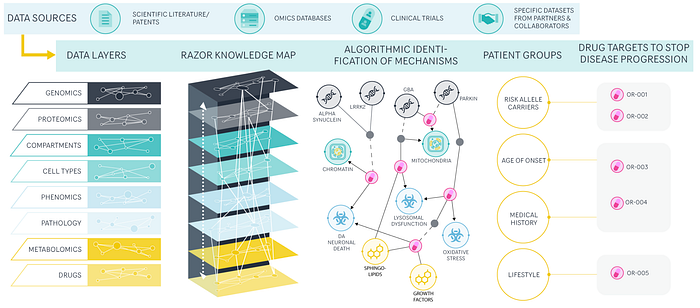
Source: OccamzRazor
Finally, against chronic diseases, Precision life, a UK-based, Series A company uses combinatorial analytics for drug discovery and patient stratification, facilitating personalized treatment and enhanced diagnosis of chronic conditions via their proprietary DiseaseBank.
In conclusion, the AI and Genomics landscape for drug discovery is rich, diverse, and full of potential. The dynamic interplay between AI-focused Tool Providers and AI-focused Biopharma catalyzes breakthroughs, enhances our understanding of complex diseases, and paves the way toward more effective, personalized treatments.
The Drivers of Success Remain the Same for Both Approaches: Deep Sector Expertise and Rich Databases
Two fundamental Key Drivers of Success stand out in AI and Genomics for drug discovery: Sizeable and Dynamic Multi-Omics Databases in AI-Powered Algorithms and Wet Lab Capabilities.
Sizeable and Dynamic Multi-Omics Databases in AI-Powered Algorithms form the foundation of efficient drug discovery. The power and accuracy of AI tools in identifying unique drug targets correlate with the size and diversity of these databases. A robust database ideally houses over 10,000 data points spanning a spectrum of metrics from genomic and proteomic to phenotypic factors, gathered at various significant time points. This breadth and depth of orthogonal (mutually independent) data sets empower AI to reveal new patterns or relationships that traditional methods would take decades and colossal funds to uncover.
On the other hand, Wet Lab Capabilities represent the tangible biochemical and biological experiments executed at the bench side. Despite AI tools’ aim to downsize traditional discovery and preclinical work in drug R&D, integrating bench side assays to test potential drug candidates enhances the precision and accuracy of results. This process enables a more effective “design-build-test-learn” cycle. Algorithms incorporating both successful and unsuccessful assay outcomes can identify successful candidates and those with failure-prone characteristics. Conversely, algorithms trained solely on published data or past successful candidates can be inherently biased due to the lack of a broader context.
Conclusion
We are entering an exciting time in drug discovery, powered by the combination of AI and data from multi-omics sources. AI-focused Tool Providers and AI-focused Biopharma are spearheading this effort, using their unique strengths to pave the way toward personalized medicine.
The path to success is built on two main elements: having large databases of genomic data that AI can learn from and leveraging partnerships to carry out real-world laboratory experiments. These two pieces of the puzzle can help us make sense of complex data and develop new treatments.
There are certainly challenges to overcome, but the opportunities are huge. As we progress on this path, we’re looking forward to seeing what new discoveries will be made where AI, genomics, and drug discovery intersect.
We want to hear from you!
We are curious to hear your thoughts and ideas. If you’re working on AI applications in omics data, for biomarker identification, drug discovery, or to enhance clinical trials, please reach out to us.
Summary
TL;DR
The application of multi-omics data with AI offers a very exciting opportunity for VC investments.
AI and multi-omics data are revolutionizing disease understanding: AI and multi-omics data (detailed data about our genes, proteins, and other biological elements) are working together to speed up the creation of new medicines and treatments. These new tools are transforming drug discovery, and development by enabling efficient biomarker identification, drug target discovery, and cost-effective vertical integration.
Startups in that field face tough challenges: AI and multi-omics companies are faced with data management, regulatory challenges, and the high standards to validate their insights with Pharma companies.
Agnostic tool providers or disease specific biopharma are the two main winning approaches: Two types of companies stand out in this field: AI-focused Tool Providers, who create systems for drug discovery, and AI-focused Biopharma, who use these systems to find new drugs.
Dynamic databases and deep sector knowledge are drivers of success: The big databases used by AI systems and the ability to test ideas in labs are crucial for success in drug discovery using AI and genomics.
Introduction
We stand at the cusp of a transformative era in the treatment and drug discovery industry. Two key drivers have come together in a potent, symbiotic relationship: the exponential growth of data related to the functioning of the human body, and our ability to extract valuable insights from this complex data stream, thanks to the advances of Artificial Intelligence (AI).
Multi-genomic data is a game-changer in our quest to understand the intricate molecular complexities and variations associated with diverse health conditions. It provides invaluable insights into the complex interplay among various biomolecules and their functions within the human body.
Take, for instance, identical twins. While they share the same genome and are more likely to share health conditions, they don’t always exhibit the same diseases, particularly complex disorders like schizophrenia. This fact underscores the multifaceted nature of human health and disease. We cannot approach diseases only through the prism of genetics but rather through multiple factors — our genome, epigenetics (stable changes in gene expression that do not involve DNA sequence modifications), metabolomics, and microbiome, among others. This is what multi-omics data encompasses.
However, it’s crucial to note that multi-omics data alone doesn’t deliver the necessary actionable insights. This is where the critical role of Artificial Intelligence (AI) comes into sharp focus. AI is primed to help us discern relevant patterns within complex data, translating this complexity into more manageable forms and eventually revealing patterns that can guide understanding and actions.
This powerful convergence of AI and multi-omics data is steering us towards precision medicine, markedly enriching our understanding of disease processes and accelerating the discovery and development of innovative therapeutic solutions.
We at Pace Ventures have been exploring the space and its challenges and found exciting approaches and companies trying to provide new treatments to diseases affecting millions of us. Read more about our findings below.
Source: Merck
A Deeper Dive: What Is Multi-Omics Data and Why Is It Critical?
Consider our body a bustling city, with each cell as a distinct building hosting various activities. Each “building” or cell has numerous departments, like a design department (our genes), a manufacturing department (proteins), a communication department (RNA), and others. In biological terms, these departments are the various “omics” — genomics, proteomics, transcriptomics, etc.
To understand how this city operates — how it responds to changes, grows, or even breaks down (as in diseases), it’s not sufficient to look at one department at a time. A comprehensive understanding requires insight into how these departments interact and influence each other. This comprehensive insight is the essence of multi-omics.
Multi-omics offers a holistic overview, akin to a city planner considering all departments across all buildings. Scientists leveraging multi-omics gain rich insights into our body’s functioning in health and disease. They can unearth precise disease details, guiding the design of more specific treatments for individuals — akin to tailoring a suit to fit perfectly. This is the concept of precision medicine — delivering the right treatment, to the right person, at the right time.
However, multi-omics, like city planning, is a complex field. It involves a lot of information, necessitating specialized tools and techniques for effective processing.
Now enters AI.
AI plays a pivotal role in analyzing this wealth of data. Firstly, AI can integrate different types of multi-omics data, such as genomic, proteomic, metabolomic, and other omic data types. This integration provides a more comprehensive understanding of a patient’s physiological state, facilitating accurate disease diagnosis and prognosis and enabling precise and personalized treatment strategies.
Furthermore, AI algorithms can drastically reduce the dimensionality of multi-omics, enabling researchers to extract valuable insights from intricate biological processes. These insights can help understand disease processes better, identify potential therapeutic targets, and develop personalized treatment plans.
AI can also incorporate other data types into multi-omics analyses, like imaging, clinical, environmental, and social determinant data. This creates a more holistic view of patient health, facilitates better treatment decisions, and improves patient outcomes.
The relevance of using AI and multi-omics is already clear. For example, the Rady Children’s Institute for Genomic Medicine used AI to cut diagnosis time for rare genetic disorders in newborns to 19.5 hours. The technology rapidly analyzed multi-omics data and identified genetic variants. It enabled the swift diagnosis and treatment of an 8-day-old baby with a rare condition, demonstrating the transformative potential of AI in genomic medicine, particularly for rare diseases in pediatric settings.
The marriage of AI and multi-omics data is a revolution in healthcare that is already in effect, accelerating the path toward personalized medicine and fundamentally reshaping the drug discovery industry.
Market Trends
Innovation Leaps and Growing R&D Inefficiencies in Pharma: A Paradox
In recent years, groundbreaking innovation has radically transformed scientific research, bringing together the realms of multi-omics data and Artificial Intelligence. With the plummeting cost of genome sequencing and the rapid rise in GPU computing performance, the floodgates to an era of unprecedented data collection and fast data processing have been opened wide (see figures 1 and 2).
Figure 1: Cost of genome sequencing
Figure 2: GPU performance in operations per second (source)
Thanks to these key developments, we are now awash in information. For perspective, approximately 30 million individuals have had their genomes sequenced, with each genome containing around 3 billion nucleotide pairs.
Key players in the biomedical sector — from biopharma firms and academic researchers to government research groups such as the National Cancer Institutes, NIH, and the U.K. Biobank — are generating large omics datasets using cutting-edge tools. These tools include genomic sequencers for DNA, single-cell RNA sequencing, and spatial proteomics platforms, but also contextualize such data through phenotype level information, like remote monitoring devices (smartwatches and smartphones), and digitally enabled tools such as insulin pumps and prescription digital therapeutics.
Despite these significant advances and the abundance of data generated, there is an unexpected stagnation in R&D efficiency within the pharmaceutical and genomics sectors. The cost of drug discovery and the time required to develop drugs have paradoxically increased — a phenomenon first noted in the 1980s and referred to as “Eroome’s Law” by Jack Scannell in a 2012 Nature publication (Moore’s Law spelled backward). Between 2001 and 2020, R&D costs increased by 13.7% annually, while the number of drugs approved increased by only 7.2% YoY over the same period. It is estimated that developing a new drug takes around 10 years and costs more than US$ 2 billion.
Source: Congressional Budget Office
Given these challenges, there’s a pressing need for innovation in pharmaceutical R&D. A promising solution could lie in harnessing the transformative power of AI and multi-omics, potentially ushering in a new era of efficiency and productivity in therapeutic discovery and development.
Market Dynamics: Large Pharma-AI Deals Fueling Strong Growth
The AI in drug discovery market is experiencing remarkable growth, with new players landing billion-dollar contracts. Over the last two years, a staggering $32 billion in deal value has been created through strategic partnerships between large pharmaceutical companies and AI-focused firms. For instance, in January 2022, Exscientia, an AI-driven drug discovery company, clinched a huge US$5.2 billion deal, the largest in the history of AI deals, with Sanofi.
Hence, this attracts massive capital investments, with funds injected into AI-powered drug discovery firms that have tripled over the past four years. This surge resulted in US$24.6 billion in investments in 2022 alone.
Simultaneously, the global single-cell multi-omics market (omics data at the cell level) is projected to skyrocket from $1.43 billion in 2022 to $7.72 billion by 2033, growing at a CAGR of 17.27% during the forecast period 2023–2033.
Cumulative Capital Investments in AI in Drug Development Companies (Source)
Looking toward the future, the potential revenue derived from incorporating AI in drug discovery appears boundless. This market is estimated to represent a $50 billion opportunity for big pharmaceutical companies. Using AI in early-stage drug development could yield 50 novel therapies, translating into over $50 billion in sales.
Given this vast growth potential, the future of AI-driven drug discovery is promising.
Opportunities
Unlocking Understanding of Complex Diseases: Biomarker Discovery
Biomarkers, crucial biological molecules, can reveal a disease’s presence, progression, or severity. They also serve as a gauge for the effectiveness of treatments. For instance, a certain condition might prompt elevated levels of a specific protein in the blood. This protein’s level might then decrease in response to effective treatment. Biomarkers enable researchers to categorize disease severity, measure clinical benefits or harm from therapeutic intervention, and monitor treatment responses.
Traditionally, researchers struggled to identify new biomarkers for diseases, as interpreting colossal amounts of data was impossible, and sifting through ‘noise’ to gain precious insights was very challenging.
AI techniques prove invaluable for analyzing and extracting biomarkers from integrated data. When combining different omics layers, researchers can use biomarkers to provide a more granular understanding of a disease, moving away from binary outcomes. This helps to categorize diseases into subtypes, craft predictive models for diagnosis and treatment response, and identify disease-associated pathways.
For example, Aladdin (acquired by International Biotechnology Corp.) has constructed a platform for early diagnostics of Alzheimer’s disease and COVID-19 by identifying new biomarkers for the onset detection of the conditions. This Disease Diagnosis platform utilizes AI and multi-omics data, imaging, blood samples, and medical records.
Revolutionizing the Drug Discovery Process: Drug Target Discovery
Drug targets, often proteins or genes, are specific molecules within the body that are designed to interact with drugs. These interactions can modify the target’s behavior, leading to therapeutic effects. Drug targets often form part of larger networks of interactions (or pathways) that lead to a disease phenotype, making the effect of the drug-target interaction on disease symptoms complex. Drug targets are typically discovered and validated through intensive biological and genetic research.
With techniques like network analysis, or graph-based Machine learning, it is possible to represent complex molecular reactions like a network. Analyzing these molecular interaction networks allows us to identify key nodes or proteins that are essential in disease pathways. By integrating multi-omics data with existing knowledge of molecular interactions, AI can identify potential drug targets that are crucial for disease progression and have the potential to be modulated by therapeutic interventions.
In September 2019, Deep Genomics’ (US-based) AI-driven platform leveraged a graph-based interpretation of multi-omics data to predict a novel drug target and a drug candidate for Wilson disease in less than 18 months. The platform analyzed multi-omics data and screened 100,000 genomics mutations to identify the precise disease-causing mechanism of a specific mutation.
Vertical Integration in Drug Development
Vertical integration in the drug development value chain presents a significant opportunity for companies to maximize profits. Most costs associated with drug development arise during the clinical phases, where extensive drug testing takes place. The quality assurance of the drug becomes a major bottleneck in the process. By enhancing the efficiency of the drug, companies can unlock substantial cost reductions.
Source: The Cowen Insight
AI and omics data are reshaping the way we discover drugs. They help us create predictive models that understand how drugs work at a molecular level, leading to more targeted treatments.
AI can also search through large databases to find potential new drugs. This process, called virtual screening, uses methods like molecular docking and machine learning. It’s especially useful in repurposing existing drugs for new uses.
More and more drug companies are making these techniques a core part of their work, focusing specifically on diseases. Using AI and omics data not only improves the quality of the drugs they make but also offers big benefits. It can help lower costs, create more value, and open up chances for important partnerships. This is great for both big companies and newcomers.
In fact, this approach of combining technology and a disease-specific focus is now the way forward for the most successful companies in AI drug discovery.
Insilico Medicine, an end-to-end AI-driven drug discovery company, announced the commencement of clinical trials for the first fully AI-generated drug to treat idiopathic pulmonary fibrosis, a chronic lung disease. They have pioneered the path in the pharmaceutical industry by being the foremost to reach this advanced stage in the development process with a drug entirely conceived by artificial intelligence. Simultaneously, their proprietary end-to-end platform was actively deployed and refined in parallel with the progression of the drug through its development stages. In June 2022, they reached a US$ 900 million valuation and filed in June 2023 for an IPO.
The Challenges
Data-Related Obstacles Faced by AI & Omics Companies
AI and Omics companies grapple with challenges related to data management and utilization. While AI tools are adept at processing and interpreting vast datasets, their outputs are only as accurate as the data inputs, i.e., the “garbage in equals garbage out” principle. This means that misinterpretation or misuse of data can lead to flawed results, particularly consequential in drug discovery.
First, data generation, which involves creating and tracking data back to its origin, is crucial. It calls for sector-specific expertise and a thorough understanding of how the data was produced.
Next is data aggregation, which involves collating and normalizing data to construct a comprehensive multi-omics database. However, accessing genomic data is costly and involves regulatory complexities, often necessitating a dedicated commercial or sales team to access and integrate these datasets into a given database.
Further complexity arises from data contextualization, integrating other data sources, like Electronic Health Records (EHR). However, EHR data is notoriously complex and messy, lacking standardization, which impedes systematic usage across different populations and systems.
Lastly, AI and Omics companies must grapple with stringent regulatory scrutiny, especially when accessing medical data between countries like the European Union and the United States. These restrictions limit companies’ data storage abilities and influence their choice of server hosting companies, which could be limiting factors in a company’s development.
Correlation Does Not Imply Causality
Results from in silico, or computer-simulated studies, often hinge on retrospective analysis, analyzing past data, which can inadvertently introduce bias compared to prospective studies (in vivo experiments). These future studies analyze new data based on predefined parameters, reducing bias risk.
However, the reliability of in silico results can be significantly bolstered if cross-verified across multiple independent data sets or backed up by useful data in an iterative or supplementary manner. Essentially, if the simulated results can be repeated or validated with different data sets, or supplemented by experimental data, their reliability likely increases.
Interesting Approaches and Companies in the Field
Two Different Approaches in the AI & Genomics for the Drug Discovery Space
In AI and Genomics for drug discovery, two types of approaches are distinctly noticeable for startups: AI-focused Tool Providers and AI-focused Biopharma. Nevertheless, these two company approaches share common drivers for success, as they both require deep expertise combined with rich and dynamic databases.
AI-focused Tool Providers
AI-focused Tool Providers possess extensive multi-omics databases, often complemented by other data sources. They are marked by high-caliber computer science expertise and a focus on developing innovative AI platforms applicable across various biopharma products.
An example is the Swiss-based, early-stage company, Genomsys. The company has developed an ISO standard for complex genomics data and use it to build AI tools. Another approach is Pheiron, a Berlin-based company at the pre-seed stage. Pheiron offers a plug-and-play platform that integrates large amounts of multi-omics data from various databases and leveraging AI models to extract biomarkers for complex diseases.
Similarly, Genpax (UK-based, late-stage) developed faster sequencing for high-resolution pathogen analysis to deliver reproducible results through their platform, serving diverse industries.
These tool providers place great emphasis on Collaboration and Refinement, constantly improved their service based on the results achieved through their partnerships. Biotx.ai, for instance, is pioneering a Wide Data approach, shifting from the Big Data approach many algorithms rely on, to learn complex patterns from a small number of genomic data.
Simultaneously, these providers also aim at Expansion Across different Therapeutic Areas, broadening the scope of their AI capabilities across applied on different diseases and drug development phases.
Protai, an Israel-based Series A company, uses mass spec-derived proteomics data and other protein datasets to simulate disease on the molecular level. Their vertically integrated platform is tailored for drug discovery but remains applicable to various therapeutics.
France-based Series A WhiteLab Genomics, focuses on gene therapy research. They offer a platform that enables in-silico predictions for target discovery and the design of DNA & RNA therapies.
Deepflare, early stage and Poland-based, applies computational algorithms and machine learning for personalized cancer therapies and drug design optimization while integrating lab automation for accelerated, data-driven drug development.
Scailyte, a Swiss-based early-stage company, generates insights from multi-omics single-cell data using AI for CAR-T cell therapies. Their AI platform, ScaiVision, is used by clinical and industry partners to drive a pipeline of five targets today, addressing various clinical needs. Similarly, UK-based early-stage company Coding.bio also integrates AI for rapid discovery, testing, and optimization of novel CARs, enhancing clinical outcomes.
AI-focused Biopharma
AI-focused Biopharma, in contrast, build their own resources, such as supercomputing power and algorithms. They rely on multi-omics databases they developed internally through exclusive partnerships with hospitals and other third parties. They aim to discover drug candidates within their therapeutic area of focus using their proprietary AI tools. AI-focused Biopharma aim to identify unique, differentiated drug candidates for clinical testing and eventual market release. That is what our great portfolio company Celeris Therapeutics does. They use machine learning to design proximity-inducing compounds (PICs™) and new chemical entities, focusing on treating high-need diseases, particularly in oncology and CNS disorders, through targeted protein degradation.
Yet, these AI-focused biopharma often rely on External Partnerships for AI tools or applications outside of their core focus. They seek external expertise for areas beyond drug discovery, like clinical trial design, biomarker selection, and other preclinical or clinical applications.
Several companies focus on specific diseases, like oncology, cardiovascular diseases, and neurodegenerative diseases. In oncology, France-based early-stage company Orakl.bio utilizes tumor avatars that combine advanced biology and deep patient data to identify relevant drug targets using proprietary tumor data. They offer a platform that matches their tumor models with detailed clinical and omics data with AI for a comprehensive understanding of the biological results and validate the results with a proprietary wet lab.
In the fight against cardiovascular diseases, G3 therapeutics and Cardiatec Biosciences are at the forefront. US-based G3 therapeutics combines deep biological big data, machine learning, and artificial intelligence for drug discovery through the preclinical stages in cardiovascular therapeutics. UK-based CardiaTec applies artificial intelligence on large-scale multi-omic data to develop the next generation of cardiovascular disease drug targets, creating a proprietary database of heart tissues for a multi-omics dataset.
Against metabolic disorders, Multiomic Health, a UK-based seed stage company identifies unique patient profiles to generate proprietary multi-omics data for repositioning existing drugs, and discovering new ones via their MOHSAIC® platform.
In the battle against neurodegenerative diseases, OccamzRazor and Human Centric Drug Discovery are prominent examples. US-based OccamzRazor leverages various ML algorithms (NLP, Graph-based models) with multi-omics data to identify drug targets for the treatment of Parkinson’s disease. Human Centric Drug Discovery, a UK-based early-stage company, integrates data from induced pluripotent stem cells, genetic studies, and population health data to identify and validate efficient drug targets for neurological diseases.
Source: OccamzRazor
Finally, against chronic diseases, Precision life, a UK-based, Series A company uses combinatorial analytics for drug discovery and patient stratification, facilitating personalized treatment and enhanced diagnosis of chronic conditions via their proprietary DiseaseBank.
In conclusion, the AI and Genomics landscape for drug discovery is rich, diverse, and full of potential. The dynamic interplay between AI-focused Tool Providers and AI-focused Biopharma catalyzes breakthroughs, enhances our understanding of complex diseases, and paves the way toward more effective, personalized treatments.
The Drivers of Success Remain the Same for Both Approaches: Deep Sector Expertise and Rich Databases
Two fundamental Key Drivers of Success stand out in AI and Genomics for drug discovery: Sizeable and Dynamic Multi-Omics Databases in AI-Powered Algorithms and Wet Lab Capabilities.
Sizeable and Dynamic Multi-Omics Databases in AI-Powered Algorithms form the foundation of efficient drug discovery. The power and accuracy of AI tools in identifying unique drug targets correlate with the size and diversity of these databases. A robust database ideally houses over 10,000 data points spanning a spectrum of metrics from genomic and proteomic to phenotypic factors, gathered at various significant time points. This breadth and depth of orthogonal (mutually independent) data sets empower AI to reveal new patterns or relationships that traditional methods would take decades and colossal funds to uncover.
On the other hand, Wet Lab Capabilities represent the tangible biochemical and biological experiments executed at the bench side. Despite AI tools’ aim to downsize traditional discovery and preclinical work in drug R&D, integrating bench side assays to test potential drug candidates enhances the precision and accuracy of results. This process enables a more effective “design-build-test-learn” cycle. Algorithms incorporating both successful and unsuccessful assay outcomes can identify successful candidates and those with failure-prone characteristics. Conversely, algorithms trained solely on published data or past successful candidates can be inherently biased due to the lack of a broader context.
Conclusion
We are entering an exciting time in drug discovery, powered by the combination of AI and data from multi-omics sources. AI-focused Tool Providers and AI-focused Biopharma are spearheading this effort, using their unique strengths to pave the way toward personalized medicine.
The path to success is built on two main elements: having large databases of genomic data that AI can learn from and leveraging partnerships to carry out real-world laboratory experiments. These two pieces of the puzzle can help us make sense of complex data and develop new treatments.
There are certainly challenges to overcome, but the opportunities are huge. As we progress on this path, we’re looking forward to seeing what new discoveries will be made where AI, genomics, and drug discovery intersect.
We want to hear from you!
We are curious to hear your thoughts and ideas. If you’re working on AI applications in omics data, for biomarker identification, drug discovery, or to enhance clinical trials, please reach out to us.
Summary
TL;DR
The application of multi-omics data with AI offers a very exciting opportunity for VC investments.
AI and multi-omics data are revolutionizing disease understanding: AI and multi-omics data (detailed data about our genes, proteins, and other biological elements) are working together to speed up the creation of new medicines and treatments. These new tools are transforming drug discovery, and development by enabling efficient biomarker identification, drug target discovery, and cost-effective vertical integration.
Startups in that field face tough challenges: AI and multi-omics companies are faced with data management, regulatory challenges, and the high standards to validate their insights with Pharma companies.
Agnostic tool providers or disease specific biopharma are the two main winning approaches: Two types of companies stand out in this field: AI-focused Tool Providers, who create systems for drug discovery, and AI-focused Biopharma, who use these systems to find new drugs.
Dynamic databases and deep sector knowledge are drivers of success: The big databases used by AI systems and the ability to test ideas in labs are crucial for success in drug discovery using AI and genomics.
Introduction
We stand at the cusp of a transformative era in the treatment and drug discovery industry. Two key drivers have come together in a potent, symbiotic relationship: the exponential growth of data related to the functioning of the human body, and our ability to extract valuable insights from this complex data stream, thanks to the advances of Artificial Intelligence (AI).
Multi-genomic data is a game-changer in our quest to understand the intricate molecular complexities and variations associated with diverse health conditions. It provides invaluable insights into the complex interplay among various biomolecules and their functions within the human body.
Take, for instance, identical twins. While they share the same genome and are more likely to share health conditions, they don’t always exhibit the same diseases, particularly complex disorders like schizophrenia. This fact underscores the multifaceted nature of human health and disease. We cannot approach diseases only through the prism of genetics but rather through multiple factors — our genome, epigenetics (stable changes in gene expression that do not involve DNA sequence modifications), metabolomics, and microbiome, among others. This is what multi-omics data encompasses.
However, it’s crucial to note that multi-omics data alone doesn’t deliver the necessary actionable insights. This is where the critical role of Artificial Intelligence (AI) comes into sharp focus. AI is primed to help us discern relevant patterns within complex data, translating this complexity into more manageable forms and eventually revealing patterns that can guide understanding and actions.
This powerful convergence of AI and multi-omics data is steering us towards precision medicine, markedly enriching our understanding of disease processes and accelerating the discovery and development of innovative therapeutic solutions.
We at Pace Ventures have been exploring the space and its challenges and found exciting approaches and companies trying to provide new treatments to diseases affecting millions of us. Read more about our findings below.
Source: Merck
A Deeper Dive: What Is Multi-Omics Data and Why Is It Critical?
Consider our body a bustling city, with each cell as a distinct building hosting various activities. Each “building” or cell has numerous departments, like a design department (our genes), a manufacturing department (proteins), a communication department (RNA), and others. In biological terms, these departments are the various “omics” — genomics, proteomics, transcriptomics, etc.
To understand how this city operates — how it responds to changes, grows, or even breaks down (as in diseases), it’s not sufficient to look at one department at a time. A comprehensive understanding requires insight into how these departments interact and influence each other. This comprehensive insight is the essence of multi-omics.
Multi-omics offers a holistic overview, akin to a city planner considering all departments across all buildings. Scientists leveraging multi-omics gain rich insights into our body’s functioning in health and disease. They can unearth precise disease details, guiding the design of more specific treatments for individuals — akin to tailoring a suit to fit perfectly. This is the concept of precision medicine — delivering the right treatment, to the right person, at the right time.
However, multi-omics, like city planning, is a complex field. It involves a lot of information, necessitating specialized tools and techniques for effective processing.
Now enters AI.
AI plays a pivotal role in analyzing this wealth of data. Firstly, AI can integrate different types of multi-omics data, such as genomic, proteomic, metabolomic, and other omic data types. This integration provides a more comprehensive understanding of a patient’s physiological state, facilitating accurate disease diagnosis and prognosis and enabling precise and personalized treatment strategies.
Furthermore, AI algorithms can drastically reduce the dimensionality of multi-omics, enabling researchers to extract valuable insights from intricate biological processes. These insights can help understand disease processes better, identify potential therapeutic targets, and develop personalized treatment plans.
AI can also incorporate other data types into multi-omics analyses, like imaging, clinical, environmental, and social determinant data. This creates a more holistic view of patient health, facilitates better treatment decisions, and improves patient outcomes.
The relevance of using AI and multi-omics is already clear. For example, the Rady Children’s Institute for Genomic Medicine used AI to cut diagnosis time for rare genetic disorders in newborns to 19.5 hours. The technology rapidly analyzed multi-omics data and identified genetic variants. It enabled the swift diagnosis and treatment of an 8-day-old baby with a rare condition, demonstrating the transformative potential of AI in genomic medicine, particularly for rare diseases in pediatric settings.
The marriage of AI and multi-omics data is a revolution in healthcare that is already in effect, accelerating the path toward personalized medicine and fundamentally reshaping the drug discovery industry.
Market Trends
Innovation Leaps and Growing R&D Inefficiencies in Pharma: A Paradox
In recent years, groundbreaking innovation has radically transformed scientific research, bringing together the realms of multi-omics data and Artificial Intelligence. With the plummeting cost of genome sequencing and the rapid rise in GPU computing performance, the floodgates to an era of unprecedented data collection and fast data processing have been opened wide (see figures 1 and 2).
Figure 1: Cost of genome sequencing
Figure 2: GPU performance in operations per second (source)
Thanks to these key developments, we are now awash in information. For perspective, approximately 30 million individuals have had their genomes sequenced, with each genome containing around 3 billion nucleotide pairs.
Key players in the biomedical sector — from biopharma firms and academic researchers to government research groups such as the National Cancer Institutes, NIH, and the U.K. Biobank — are generating large omics datasets using cutting-edge tools. These tools include genomic sequencers for DNA, single-cell RNA sequencing, and spatial proteomics platforms, but also contextualize such data through phenotype level information, like remote monitoring devices (smartwatches and smartphones), and digitally enabled tools such as insulin pumps and prescription digital therapeutics.
Despite these significant advances and the abundance of data generated, there is an unexpected stagnation in R&D efficiency within the pharmaceutical and genomics sectors. The cost of drug discovery and the time required to develop drugs have paradoxically increased — a phenomenon first noted in the 1980s and referred to as “Eroome’s Law” by Jack Scannell in a 2012 Nature publication (Moore’s Law spelled backward). Between 2001 and 2020, R&D costs increased by 13.7% annually, while the number of drugs approved increased by only 7.2% YoY over the same period. It is estimated that developing a new drug takes around 10 years and costs more than US$ 2 billion.
Source: Congressional Budget Office
Given these challenges, there’s a pressing need for innovation in pharmaceutical R&D. A promising solution could lie in harnessing the transformative power of AI and multi-omics, potentially ushering in a new era of efficiency and productivity in therapeutic discovery and development.
Market Dynamics: Large Pharma-AI Deals Fueling Strong Growth
The AI in drug discovery market is experiencing remarkable growth, with new players landing billion-dollar contracts. Over the last two years, a staggering $32 billion in deal value has been created through strategic partnerships between large pharmaceutical companies and AI-focused firms. For instance, in January 2022, Exscientia, an AI-driven drug discovery company, clinched a huge US$5.2 billion deal, the largest in the history of AI deals, with Sanofi.
Hence, this attracts massive capital investments, with funds injected into AI-powered drug discovery firms that have tripled over the past four years. This surge resulted in US$24.6 billion in investments in 2022 alone.
Simultaneously, the global single-cell multi-omics market (omics data at the cell level) is projected to skyrocket from $1.43 billion in 2022 to $7.72 billion by 2033, growing at a CAGR of 17.27% during the forecast period 2023–2033.
Cumulative Capital Investments in AI in Drug Development Companies (Source)
Looking toward the future, the potential revenue derived from incorporating AI in drug discovery appears boundless. This market is estimated to represent a $50 billion opportunity for big pharmaceutical companies. Using AI in early-stage drug development could yield 50 novel therapies, translating into over $50 billion in sales.
Given this vast growth potential, the future of AI-driven drug discovery is promising.
Opportunities
Unlocking Understanding of Complex Diseases: Biomarker Discovery
Biomarkers, crucial biological molecules, can reveal a disease’s presence, progression, or severity. They also serve as a gauge for the effectiveness of treatments. For instance, a certain condition might prompt elevated levels of a specific protein in the blood. This protein’s level might then decrease in response to effective treatment. Biomarkers enable researchers to categorize disease severity, measure clinical benefits or harm from therapeutic intervention, and monitor treatment responses.
Traditionally, researchers struggled to identify new biomarkers for diseases, as interpreting colossal amounts of data was impossible, and sifting through ‘noise’ to gain precious insights was very challenging.
AI techniques prove invaluable for analyzing and extracting biomarkers from integrated data. When combining different omics layers, researchers can use biomarkers to provide a more granular understanding of a disease, moving away from binary outcomes. This helps to categorize diseases into subtypes, craft predictive models for diagnosis and treatment response, and identify disease-associated pathways.
For example, Aladdin (acquired by International Biotechnology Corp.) has constructed a platform for early diagnostics of Alzheimer’s disease and COVID-19 by identifying new biomarkers for the onset detection of the conditions. This Disease Diagnosis platform utilizes AI and multi-omics data, imaging, blood samples, and medical records.
Revolutionizing the Drug Discovery Process: Drug Target Discovery
Drug targets, often proteins or genes, are specific molecules within the body that are designed to interact with drugs. These interactions can modify the target’s behavior, leading to therapeutic effects. Drug targets often form part of larger networks of interactions (or pathways) that lead to a disease phenotype, making the effect of the drug-target interaction on disease symptoms complex. Drug targets are typically discovered and validated through intensive biological and genetic research.
With techniques like network analysis, or graph-based Machine learning, it is possible to represent complex molecular reactions like a network. Analyzing these molecular interaction networks allows us to identify key nodes or proteins that are essential in disease pathways. By integrating multi-omics data with existing knowledge of molecular interactions, AI can identify potential drug targets that are crucial for disease progression and have the potential to be modulated by therapeutic interventions.
In September 2019, Deep Genomics’ (US-based) AI-driven platform leveraged a graph-based interpretation of multi-omics data to predict a novel drug target and a drug candidate for Wilson disease in less than 18 months. The platform analyzed multi-omics data and screened 100,000 genomics mutations to identify the precise disease-causing mechanism of a specific mutation.
Vertical Integration in Drug Development
Vertical integration in the drug development value chain presents a significant opportunity for companies to maximize profits. Most costs associated with drug development arise during the clinical phases, where extensive drug testing takes place. The quality assurance of the drug becomes a major bottleneck in the process. By enhancing the efficiency of the drug, companies can unlock substantial cost reductions.
Source: The Cowen Insight
AI and omics data are reshaping the way we discover drugs. They help us create predictive models that understand how drugs work at a molecular level, leading to more targeted treatments.
AI can also search through large databases to find potential new drugs. This process, called virtual screening, uses methods like molecular docking and machine learning. It’s especially useful in repurposing existing drugs for new uses.
More and more drug companies are making these techniques a core part of their work, focusing specifically on diseases. Using AI and omics data not only improves the quality of the drugs they make but also offers big benefits. It can help lower costs, create more value, and open up chances for important partnerships. This is great for both big companies and newcomers.
In fact, this approach of combining technology and a disease-specific focus is now the way forward for the most successful companies in AI drug discovery.
Insilico Medicine, an end-to-end AI-driven drug discovery company, announced the commencement of clinical trials for the first fully AI-generated drug to treat idiopathic pulmonary fibrosis, a chronic lung disease. They have pioneered the path in the pharmaceutical industry by being the foremost to reach this advanced stage in the development process with a drug entirely conceived by artificial intelligence. Simultaneously, their proprietary end-to-end platform was actively deployed and refined in parallel with the progression of the drug through its development stages. In June 2022, they reached a US$ 900 million valuation and filed in June 2023 for an IPO.
The Challenges
Data-Related Obstacles Faced by AI & Omics Companies
AI and Omics companies grapple with challenges related to data management and utilization. While AI tools are adept at processing and interpreting vast datasets, their outputs are only as accurate as the data inputs, i.e., the “garbage in equals garbage out” principle. This means that misinterpretation or misuse of data can lead to flawed results, particularly consequential in drug discovery.
First, data generation, which involves creating and tracking data back to its origin, is crucial. It calls for sector-specific expertise and a thorough understanding of how the data was produced.
Next is data aggregation, which involves collating and normalizing data to construct a comprehensive multi-omics database. However, accessing genomic data is costly and involves regulatory complexities, often necessitating a dedicated commercial or sales team to access and integrate these datasets into a given database.
Further complexity arises from data contextualization, integrating other data sources, like Electronic Health Records (EHR). However, EHR data is notoriously complex and messy, lacking standardization, which impedes systematic usage across different populations and systems.
Lastly, AI and Omics companies must grapple with stringent regulatory scrutiny, especially when accessing medical data between countries like the European Union and the United States. These restrictions limit companies’ data storage abilities and influence their choice of server hosting companies, which could be limiting factors in a company’s development.
Correlation Does Not Imply Causality
Results from in silico, or computer-simulated studies, often hinge on retrospective analysis, analyzing past data, which can inadvertently introduce bias compared to prospective studies (in vivo experiments). These future studies analyze new data based on predefined parameters, reducing bias risk.
However, the reliability of in silico results can be significantly bolstered if cross-verified across multiple independent data sets or backed up by useful data in an iterative or supplementary manner. Essentially, if the simulated results can be repeated or validated with different data sets, or supplemented by experimental data, their reliability likely increases.
Interesting Approaches and Companies in the Field
Two Different Approaches in the AI & Genomics for the Drug Discovery Space
In AI and Genomics for drug discovery, two types of approaches are distinctly noticeable for startups: AI-focused Tool Providers and AI-focused Biopharma. Nevertheless, these two company approaches share common drivers for success, as they both require deep expertise combined with rich and dynamic databases.
AI-focused Tool Providers
AI-focused Tool Providers possess extensive multi-omics databases, often complemented by other data sources. They are marked by high-caliber computer science expertise and a focus on developing innovative AI platforms applicable across various biopharma products.
An example is the Swiss-based, early-stage company, Genomsys. The company has developed an ISO standard for complex genomics data and use it to build AI tools. Another approach is Pheiron, a Berlin-based company at the pre-seed stage. Pheiron offers a plug-and-play platform that integrates large amounts of multi-omics data from various databases and leveraging AI models to extract biomarkers for complex diseases.
Similarly, Genpax (UK-based, late-stage) developed faster sequencing for high-resolution pathogen analysis to deliver reproducible results through their platform, serving diverse industries.
These tool providers place great emphasis on Collaboration and Refinement, constantly improved their service based on the results achieved through their partnerships. Biotx.ai, for instance, is pioneering a Wide Data approach, shifting from the Big Data approach many algorithms rely on, to learn complex patterns from a small number of genomic data.
Simultaneously, these providers also aim at Expansion Across different Therapeutic Areas, broadening the scope of their AI capabilities across applied on different diseases and drug development phases.
Protai, an Israel-based Series A company, uses mass spec-derived proteomics data and other protein datasets to simulate disease on the molecular level. Their vertically integrated platform is tailored for drug discovery but remains applicable to various therapeutics.
France-based Series A WhiteLab Genomics, focuses on gene therapy research. They offer a platform that enables in-silico predictions for target discovery and the design of DNA & RNA therapies.
Deepflare, early stage and Poland-based, applies computational algorithms and machine learning for personalized cancer therapies and drug design optimization while integrating lab automation for accelerated, data-driven drug development.
Scailyte, a Swiss-based early-stage company, generates insights from multi-omics single-cell data using AI for CAR-T cell therapies. Their AI platform, ScaiVision, is used by clinical and industry partners to drive a pipeline of five targets today, addressing various clinical needs. Similarly, UK-based early-stage company Coding.bio also integrates AI for rapid discovery, testing, and optimization of novel CARs, enhancing clinical outcomes.
AI-focused Biopharma
AI-focused Biopharma, in contrast, build their own resources, such as supercomputing power and algorithms. They rely on multi-omics databases they developed internally through exclusive partnerships with hospitals and other third parties. They aim to discover drug candidates within their therapeutic area of focus using their proprietary AI tools. AI-focused Biopharma aim to identify unique, differentiated drug candidates for clinical testing and eventual market release. That is what our great portfolio company Celeris Therapeutics does. They use machine learning to design proximity-inducing compounds (PICs™) and new chemical entities, focusing on treating high-need diseases, particularly in oncology and CNS disorders, through targeted protein degradation.
Yet, these AI-focused biopharma often rely on External Partnerships for AI tools or applications outside of their core focus. They seek external expertise for areas beyond drug discovery, like clinical trial design, biomarker selection, and other preclinical or clinical applications.
Several companies focus on specific diseases, like oncology, cardiovascular diseases, and neurodegenerative diseases. In oncology, France-based early-stage company Orakl.bio utilizes tumor avatars that combine advanced biology and deep patient data to identify relevant drug targets using proprietary tumor data. They offer a platform that matches their tumor models with detailed clinical and omics data with AI for a comprehensive understanding of the biological results and validate the results with a proprietary wet lab.
In the fight against cardiovascular diseases, G3 therapeutics and Cardiatec Biosciences are at the forefront. US-based G3 therapeutics combines deep biological big data, machine learning, and artificial intelligence for drug discovery through the preclinical stages in cardiovascular therapeutics. UK-based CardiaTec applies artificial intelligence on large-scale multi-omic data to develop the next generation of cardiovascular disease drug targets, creating a proprietary database of heart tissues for a multi-omics dataset.
Against metabolic disorders, Multiomic Health, a UK-based seed stage company identifies unique patient profiles to generate proprietary multi-omics data for repositioning existing drugs, and discovering new ones via their MOHSAIC® platform.
In the battle against neurodegenerative diseases, OccamzRazor and Human Centric Drug Discovery are prominent examples. US-based OccamzRazor leverages various ML algorithms (NLP, Graph-based models) with multi-omics data to identify drug targets for the treatment of Parkinson’s disease. Human Centric Drug Discovery, a UK-based early-stage company, integrates data from induced pluripotent stem cells, genetic studies, and population health data to identify and validate efficient drug targets for neurological diseases.
Source: OccamzRazor
Finally, against chronic diseases, Precision life, a UK-based, Series A company uses combinatorial analytics for drug discovery and patient stratification, facilitating personalized treatment and enhanced diagnosis of chronic conditions via their proprietary DiseaseBank.
In conclusion, the AI and Genomics landscape for drug discovery is rich, diverse, and full of potential. The dynamic interplay between AI-focused Tool Providers and AI-focused Biopharma catalyzes breakthroughs, enhances our understanding of complex diseases, and paves the way toward more effective, personalized treatments.
The Drivers of Success Remain the Same for Both Approaches: Deep Sector Expertise and Rich Databases
Two fundamental Key Drivers of Success stand out in AI and Genomics for drug discovery: Sizeable and Dynamic Multi-Omics Databases in AI-Powered Algorithms and Wet Lab Capabilities.
Sizeable and Dynamic Multi-Omics Databases in AI-Powered Algorithms form the foundation of efficient drug discovery. The power and accuracy of AI tools in identifying unique drug targets correlate with the size and diversity of these databases. A robust database ideally houses over 10,000 data points spanning a spectrum of metrics from genomic and proteomic to phenotypic factors, gathered at various significant time points. This breadth and depth of orthogonal (mutually independent) data sets empower AI to reveal new patterns or relationships that traditional methods would take decades and colossal funds to uncover.
On the other hand, Wet Lab Capabilities represent the tangible biochemical and biological experiments executed at the bench side. Despite AI tools’ aim to downsize traditional discovery and preclinical work in drug R&D, integrating bench side assays to test potential drug candidates enhances the precision and accuracy of results. This process enables a more effective “design-build-test-learn” cycle. Algorithms incorporating both successful and unsuccessful assay outcomes can identify successful candidates and those with failure-prone characteristics. Conversely, algorithms trained solely on published data or past successful candidates can be inherently biased due to the lack of a broader context.
Conclusion
We are entering an exciting time in drug discovery, powered by the combination of AI and data from multi-omics sources. AI-focused Tool Providers and AI-focused Biopharma are spearheading this effort, using their unique strengths to pave the way toward personalized medicine.
The path to success is built on two main elements: having large databases of genomic data that AI can learn from and leveraging partnerships to carry out real-world laboratory experiments. These two pieces of the puzzle can help us make sense of complex data and develop new treatments.
There are certainly challenges to overcome, but the opportunities are huge. As we progress on this path, we’re looking forward to seeing what new discoveries will be made where AI, genomics, and drug discovery intersect.
We want to hear from you!
We are curious to hear your thoughts and ideas. If you’re working on AI applications in omics data, for biomarker identification, drug discovery, or to enhance clinical trials, please reach out to us.